 on [Unsplash](https://unsplash.com/photos/oWrZoAVOBS0)](https://ashdavies.dev/images/posts/oWrZoAVOBS0.jpeg)
Preface
Last year, there was a hot topic on Twitter about how relevant RxJava was with modern Android development, which garnered a pretty interesting debate with some convincing arguments from both sides.
The claim was that given the popularity of modern frameworks, RxJava is too bloated and should be removed. The debate was even given a catchy title, which prompted a panel discussion at Droidcon Berlin last year, with Hasan, Ivan, x, and myself.
The purpose of this article isn’t to go into detail on how to migrate from one framework to the other, or whether one is better than the other, but rather to emphasise the situations that might require one over the other, and where the strengths of utilisation differ.
RxMustDie

Evaluating the current landscape for Android development, it can be easy to get overexcited by new innovative trends, so it makes sense to be apprehensive. However, this doesn’t mean we shouldn’t take on new ideas and implement them where it makes sense to do so.
Kotlin was unveiled as an experimental project from JetBrains in 2011, with its first stable release appearing in 2014. In these initial years, it gathered quite a bit of support from the development community, with adoption doubling year-on-year. It wasn’t until Google had announced first class support for Android in 2017 that adoption really skyrocketed. Community involvement and participation grew exponentially, triggering talks on every aspect of Kotlin and how it integrates with our current setup; from Data Binding, Redux architecture, to the Internet of Things.
We had entered the era of Kotlin AllTheThings™
Evolution of Kotlin
By the end of 2017, GitHub had already reported over twenty-five million lines of code, and StackOverflow speculated that it was both one of the fastest growing and “least disliked” languages.
JetBrains continued to develop Kotlin into other facets of modern development, with the introduction of Kotlin Multiplatform with Kotlin 1.2 allowing developers to reuse the same code across other platforms, and not being confined to just the Java Virtual Machine.
“StackOverflow speculated that it was one of the least disliked languages”
Taking the opportunity to tackle the difficulties of asynchronous code, JetBrains introduced Kotlin Coroutines with Kotlin 1.1 (though available only with experimental support). Coroutines already exist in many other languages in some form or other, to provide subroutines for non-preemptive (cooperative) multitasking.
Kotlin Coroutines
The beauty of Coroutines in Kotlin is that it allows us to write asynchronous code, as though it were synchronous, making it possible to do away with the verbosity of heavy callbacks. Provide the execution with a Coroutine scope, and you can invoke suspended functions sequentially as though it was imperative code.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello, ")
Thread.sleep(2000L)
}
// Hello, World!
Functions marked as suspended would imply that the operations should be performed as a coroutine without immediately requiring the specification of a thread dispatcher or context. The caller would then be required to construct a Coroutine Scope, as seen above with the provision through GlobalScope, which applies an unconfined dispatcher.
Since its experimental release, Kotlin has already reached and exceeded version 1.3, where Coroutines have been promoted to stable. Though this now afforded us the use of Coroutines for most common use cases, it isn’t strictly true, as many parts of the API are still marked as experimental or carrying risk.
The fundamental usage of Coroutines rests upon the Coroutine builders async and launch, which allow you to build a Coroutine scope with a given context, and dispatcher.
The former, async, should be used when you wish to return a Deferred type, which wraps your return type and allows the consumer to “await” the result as required.
The latter, launch, is to be used when a fire-and-forget behaviour is more appropriate, and will instead return a Job which can be joined only when necessary, which will cause the current thread to await the execution without caring about the result.
Those familiar with RxJava will recognise Job as being similar to Disposable or Subscription, representing the job in progress rather than the result, which can be cancelled upon lifecycle death.
This has important implications with exception handling, as deferring the result will only throw the exception upon awaiting the result. It’s also important to note, that neither of these executions will be performed “cold”, this means that they will both execute immediately, regardless of when you await or join the invocation.
At the time of writing, Coroutines make the type Flow available under the experimental flag, allowing you to create a non-blocking asynchronous sequence of values, that will only be executed when a terminating operator (such as collect) is called. You can find more about the difference between Coroutines “hot” and “cold” streams with Roman Eli
Here be Dragons
But it’s not just Flow that’s experimental, Coroutines have reserved a few annotations to indicate parts of its API are still under development so should be used with prejudice, or extreme care.
JetBrains introduced a few annotations to manage these aspects and communicate their intentions. Though whilst these declarations may still be promoted to stable, there is a good chance they will be deprecated or removed, sometimes without support for migration.
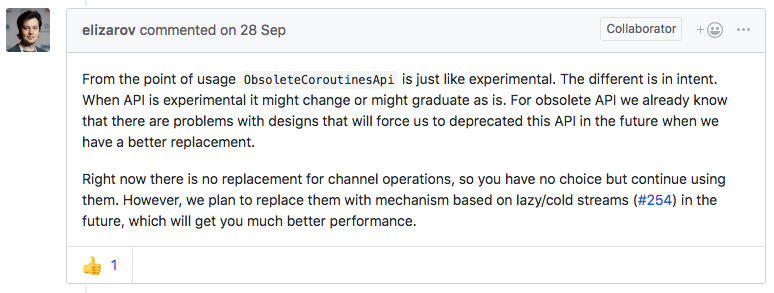
API declarations annotated with this annotation indicate that the design is still under scrutiny, and may still change, and currently applies to some RxJava conversion methods and production of channels.
Obsolete APIs indicating that the APIs will be deprecated in the future, but it is not yet known what will replace them, this currently applies to consumption of channels.
Lastly, APIs annotated with the internal annotation indicate that these should not be used anywhere except internally by Kotlin Coroutines, they can change without warning or migration aids, so should generally be avoided wherever possible.
Though the obsolete annotation can still be found on many Channel operations at the time of writing, recent updates on GitHub promote some of these APIs to experimental. It had been considered that the release of Flow would make these declarations redundant and that they could be replaced. However, with Flow now available it’s apparent that they fulfil different requirements, making the former more relevant for some use cases.
Simplicity
Despite parts of the API still being experimental, Coroutines are still widely used by developers as a concise solution to the difficulties of asynchronous code. Introducing the terse syntax and simplistic idealism’s of Kotlin into parallel subroutines with an approachable learning curve.
Part of the love for the introduction of Coroutines was that, Kotlin isn’t just a third-party library, but a native framework with first-party support from both JetBrains and Google. It enjoys continued evolution, active development of performance, features, and more importantly a refreshing turnaround on bug reports.
Many instances of platform bugs can go from an initial report to a solution being published as a snapshot build within days.
A Mired History
But it’s not just trend followers that lend Coroutines its success, the swift and widespread adoption has largely been as a result of a troubled history with asynchronous processes in Android.
Simply put, asynchronous operations on Android is hard, with earlier versions having no clear support, requiring verbose, ugly callbacks, with confusing native components, and confusing operational responsibility.
Perhaps the most difficult hurdle for developers to overcome was that there were too many choices for handling background operations, with no clear choice for most requirements. This meant developers could end up using a less than ideal solution for their projects; throw in the lack of lambda support in older versions, making simple code quite cumbersome and unreadable.
For a very long time, the official recommendation was to use AsyncTask for handling background operations in Android, which wasn’t ideal as it could easily leak context and pollute background behaviour with foreground user interface behaviour.
There have, however, been some recent developments with the inclusion of WorkManager as one of the JetPack components, which will delegate deferred background behaviour to the most appropriate services that are available on that version of Android.
A Hero Rises
Through all of this confusion, RxJava became extremely popular and a fundamental part of our modern architecture, allowing composition of complex chained sequences, and introduced reactive programming to the Android ecosystem.
Following this, a surge in libraries adopting Android framework APIs with RxJava types changed our method signatures so that everything was interoperable. Many of these implementations did a good job of providing a common framework for asynchronous operations, but also resulted in the same behaviour for synchronous or non-blocking operations.
This was further complicated with the introduction of additional reactive types in RxJava2 with no common ancestor, requiring conversion functions to map between each type. Resulting in lengthy call operator chains, mixing business behaviour and boilerplate necessary for interoperability.
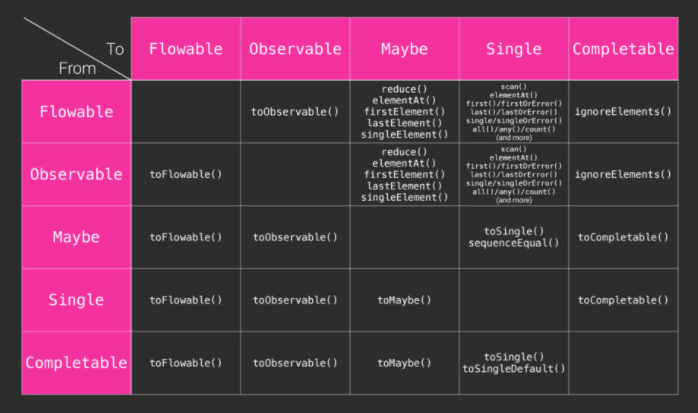
Sure Single makes sense for one-shot network operations, but requires mapping to Maybe and then Completable when used in conjunction with repository caches and side effects.
The same benefits and solutions we sought out to resolve our problems with background operations were now hurting us. With complex business behaviour being hidden, and unexpected gotchas, known only to the most elite of RxJava aficionados, resulting in unexpected and unpredictable behaviour.
The position of observeOn in an Observable chain is crucial to expected behaviour.
The sheer size of RxJava gave it a considerable memory footprint with each operation having significant allocation, making the use of RxJava to resolve most of our issues with background behaviour akin to using a sledgehammer to hammer a nail.
If all you have is a hammer, everything looks like a nail
— Abraham Maslow, The Psychology of Science, 1966
Toolkits
Due to the frustrations we had in the early days of Android, with both a lack of appropriate tooling, and an abundance of inadequate options we often made the wrong choice of an appropriate tool for the job, thus overusing RxJava to the extent of insanity.
With Coroutines now being mostly stable, this allows us to choose a more appropriate tool for simpler operations. This is not to say however, that RxJava does not have a place in our ecosystem, or that it needs to die. Simply that it is one choice of many interoperable tools at our disposal.
The new types introduced in the second revision of RxJava could now be reverted to their simpler, more predictable types. Single, used for one shot network operations, could be represented as it’s actual return type with a suspended method. Maybe could be represented as a nullable value, and Completable without one, meaning that their behaviour was more consistent with the expected behaviour of the language.
Furthermore, suspended functions need not care about which thread or context they are operated upon, but simply that they are performed aside the main sequence of operation, they are a co-routine of execution.
It’s only when consuming the method that the developer needs to construct a coroutine context which stipulates which thread the operation should be executed upon and whether exception handling should be applied.
With the addition of job hierarchy, developers can build a nested structure of execution for coroutine operations to apply consistent behaviour and task cancellation required for common Android lifecycles.
It should be noted however that whilst Coroutine behaviour reads as though it is executed sequentially and therefore could be considered imperative, it is not necessarily incompatible with a reactive architecture.
The Same, But Different
Armed with Coroutines as a native language element, we can resolve the most common of our use cases with sequentially executed statements, making our business logic clear, concise and offering significantly less cognitive load.
However, this doesn’t cover every use case, there will always be some times when we need to achieve complex composed behaviour, or adapt multiple streams of information in an immutable fashion.
For the more complex operations, Coroutines offer Channels, which can be used to connect coroutines. Channels are not a drop-in replacement for Observables, and should be considered more analogous with RxJava’s Subject type.
By design both sending and receiving data from a Channel are considered suspending, and thus don’t suffer from the same backpressure issues familiar to RxJava. RxJava had attempted to resolve the issue of backpressure with the introduction of Flowable, which required the developer to explicitly specify the behaviour when the emission of data exceeded the capacity of the consumer. Such a design was limited, and could result in unexpected behaviour in edge cases where software defects are difficult to reproduce and identify.
Though Channels still fall short of some requirements, as they are not capable of cold emission or the replaying of sequences. Furthermore, they are not well suited to the same type of transformation operations we are familiar with from RxJava, as they operate on a push-pull basis. Each transformation of a Channel results in the creation of a new Channel with the former explicitly passing data to the latter.
Recently, there has been the addition of Flow, which is described as being able to produce an asynchronous stream of events, which would only be executed with a terminal “consuming” operator. Flow appears to resolve the issue of it being too expensive to transform a stream of data with a composable operator, being closer to the operations one can perform on a List or Iterable.
At the time of writing, Flow is only available through an early access preview, and is still receiving feedback from the development community. It is annotated as experimental, so usage requires explicitly setting a runtime flag to allow its inclusion.
Though even still, neither Channel’s, nor Flow’s, are appropriate to reconstruct some behaviours in RxJava, such as building a re-playable, composable, sequential chain of operational transformations. This really is where RxJava shines, RxJava is a powerhouse. With operators for almost any operation necessary, and an API that allows developers to extend with the behaviour they require.
It need not be considered that one is better than the other, nor that one should replace the other for all use cases. They simply lie on different levels of abstraction, with RxJava obviously lying on a higher level of business behaviour.
Anecdotally, it would actually be possible to implement RxJava using coroutines, utilising the strengths of Coroutine dispatchers and language support, with the composability of Observable chains.
Therefore, it should be remembered, that RxJava still has a place in our world, and we shouldn’t rush to convert all of our existing code to Coroutines in the basis of falling victim to hype. Existing code, so long as it is tested and functional, need not be replaced.
If it ain’t broke, don’t fix it
— Bert Lance, Nation’s Business, 1977